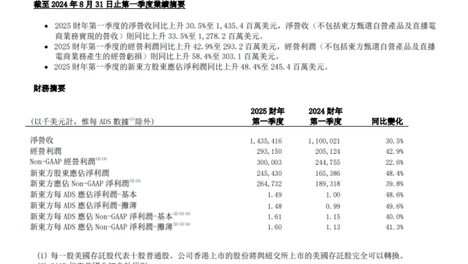
- 预测的基石:数据收集与清洗
- 数据来源的多样性
- 数据清洗的重要性
- 预测的工具:模型选择与构建
- 时间序列分析
- 回归分析
- 机器学习
- 预测的优化:模型评估与迭代
- 预测的应用:赋能决策与创新
- 结语
【新澳门直播开奖直播免费观看】,【澳门濠江论坛】,【新澳天天免费资料大全】,【2024年正版免费天天开彩】,【澳门管家婆一肖一码】,【香港4777777开奖结果+开奖结果一】,【新澳49码资料免费大全】,【2024港澳今期资料】
在信息爆炸的时代,我们每天都被海量的数据包围。如何从这些数据中提取有价值的信息,甚至预测未来的趋势,成为了各行各业都在探索的重要课题。以标题“7777788888精准新传真112,揭秘准确预测的秘密”为引,我们并非探讨某种神秘的占卜术或违法的赌博技巧,而是着重分析如何通过科学的方法、严谨的数据分析和合理的模型构建,提高预测的准确性。
预测的基石:数据收集与清洗
任何预测的准确性都依赖于高质量的数据。数据收集是第一步,我们需要确定哪些数据对预测目标有价值。例如,如果我们试图预测未来一周某电商平台的销量,那么历史销量数据、商品浏览量、用户搜索关键词、促销活动力度、天气数据等都可能是重要的输入。
数据来源的多样性
数据来源可以是多种多样的:
内部数据:例如,企业的销售记录、客户反馈、运营数据等。
公开数据:例如,政府统计数据、行业报告、新闻报道等。
第三方数据:例如,市场调研机构的数据、社交媒体数据等。
多样化的数据来源有助于我们更全面地了解影响预测目标的因素。
数据清洗的重要性
收集到的数据往往存在缺失、错误或重复的情况。数据清洗的目标就是处理这些问题,提高数据的质量。常见的数据清洗方法包括:
缺失值处理:例如,用平均值、中位数或众数填充缺失值。
异常值处理:例如,删除或修正异常值。
数据转换:例如,将不同单位的数据统一转换为同一单位。
数据标准化:例如,将数据缩放到一个特定的范围,如0到1之间。
一个干净、高质量的数据集是准确预测的必要条件。
预测的工具:模型选择与构建
有了高质量的数据,接下来就需要选择合适的模型进行预测。模型的选择取决于预测目标的类型、数据的特征以及对预测准确性的要求。常见的预测模型包括:
时间序列分析
时间序列分析适用于预测随时间变化的数据,例如股票价格、销售额、天气等。常用的时间序列模型包括:
ARIMA模型:自回归积分滑动平均模型,可以捕捉时间序列中的趋势、季节性和周期性。
指数平滑模型:对历史数据进行加权平均,权重随着时间的推移而指数衰减。
例如,我们想预测某电商平台未来一周的日均订单量。我们可以收集过去30天的日均订单量数据,使用ARIMA模型进行预测。假设过去30天的日均订单量数据如下:
7月1日:1200单,7月2日:1250单,7月3日:1300单,7月4日:1280单,7月5日:1320单,7月6日:1350单,7月7日:1400单,7月8日:1450单,7月9日:1480单,7月10日:1500单,7月11日:1550单,7月12日:1600单,7月13日:1650单,7月14日:1700单,7月15日:1750单,7月16日:1800单,7月17日:1850单,7月18日:1900单,7月19日:1950单,7月20日:2000单,7月21日:2050单,7月22日:2100单,7月23日:2150单,7月24日:2200单,7月25日:2250单,7月26日:2300单,7月27日:2350单,7月28日:2400单,7月29日:2450单,7月30日:2500单。
通过ARIMA模型分析,我们可能预测未来一周的日均订单量分别为:7月31日:2550单,8月1日:2600单,8月2日:2650单,8月3日:2700单,8月4日:2750单,8月5日:2800单,8月6日:2850单。
回归分析
回归分析用于预测一个或多个自变量对因变量的影响。例如,我们可以使用回归分析来预测广告投放量对销售额的影响。常用的回归模型包括:
线性回归:假设自变量和因变量之间存在线性关系。
多项式回归:假设自变量和因变量之间存在多项式关系。
逻辑回归:用于预测二元分类问题,例如用户是否会购买某个产品。
例如,我们想预测不同广告投放金额对应的销售额。我们收集了过去一个月的广告投放金额和销售额数据:
广告投放金额(元):1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000, 11000, 12000, 13000, 14000, 15000, 16000, 17000, 18000, 19000, 20000, 21000, 22000, 23000, 24000, 25000, 26000, 27000, 28000, 29000, 30000
销售额(元):5000, 9000, 14000, 18000, 23000, 27000, 32000, 36000, 41000, 45000, 50000, 54000, 59000, 63000, 68000, 72000, 77000, 81000, 86000, 90000, 95000, 99000, 104000, 108000, 113000, 117000, 122000, 126000, 131000, 135000
通过线性回归分析,我们可能得到一个模型:销售额 = 4.5 * 广告投放金额 + 1000。 这意味着每增加1000元广告投放,销售额预计增加4500元。
机器学习
机器学习模型可以自动从数据中学习模式,并用于预测。常用的机器学习模型包括:
决策树:根据数据的特征进行分类或回归。
支持向量机:在高维空间中找到最佳的超平面,用于分类或回归。
神经网络:模拟人脑神经元之间的连接,可以处理复杂的非线性关系。
例如,我们可以使用机器学习模型来预测用户是否会点击某个广告。我们可以收集用户的历史行为数据、广告的特征数据等,训练一个分类模型。假设我们收集到的数据包括:
用户ID,年龄,性别,兴趣爱好,广告点击率,广告展示次数,是否点击
1, 25, 男, 游戏, 0.05, 100, 1
2, 30, 女, 美妆, 0.02, 150, 0
3, 35, 男, 科技, 0.10, 80, 1
4, 40, 女, 旅游, 0.01, 200, 0
...
通过训练一个决策树模型,我们可能发现年龄在25-35岁之间,且兴趣爱好是游戏或科技的用户,点击广告的概率较高。
预测的优化:模型评估与迭代
模型构建完成后,我们需要评估其预测的准确性。常用的评估指标包括:
均方误差(MSE):衡量预测值与真实值之间的平均平方差。
均方根误差(RMSE):均方误差的平方根,更易于理解。
平均绝对误差(MAE):衡量预测值与真实值之间的平均绝对差。
R平方(R-squared):衡量模型对数据的拟合程度,取值范围为0到1,值越大表示拟合程度越高。
准确率(Accuracy):用于分类问题,衡量模型正确预测的样本比例。
精确率(Precision):用于分类问题,衡量模型预测为正例的样本中,真正例的比例。
召回率(Recall):用于分类问题,衡量模型能够找到的所有真正例的比例。
如果模型的预测准确性不满足要求,我们需要进行迭代优化。常见的优化方法包括:
增加数据量:更多的数据可以帮助模型学习更复杂的模式。
选择不同的模型:不同的模型适用于不同的数据和预测目标。
调整模型参数:优化模型的参数可以提高预测的准确性。
特征工程:从原始数据中提取更有价值的特征。
预测是一个持续迭代的过程,我们需要不断地评估和优化模型,才能提高预测的准确性。
预测的应用:赋能决策与创新
准确的预测可以帮助我们做出更好的决策,并推动创新。例如:
库存管理:预测未来一段时间的销量,可以帮助企业合理安排库存,避免缺货或积压。
营销活动:预测不同营销活动的效果,可以帮助企业选择最佳的营销策略。
风险管理:预测潜在的风险,可以帮助企业提前采取预防措施。
产品开发:预测未来的市场需求,可以帮助企业开发更符合用户需求的产品。
通过数据驱动的预测,我们可以更好地了解未来,并做出更明智的决策。
结语
“7777788888精准新传真112”并非指代某种神秘的预测方法,而是象征着我们对于精准预测的追求。通过科学的数据分析、严谨的模型构建和持续的迭代优化,我们可以不断提高预测的准确性,从而更好地应对未来的挑战。在数据驱动的时代,掌握预测的能力将成为一种核心竞争力。虽然无法保证百分之百的准确,但不断学习和实践,我们可以无限接近那个精准预测的目标。
相关推荐:1:【新澳六开彩资料2024】 2:【2024年正版资料免费大全亮点】 3:【2023管家婆精准资料大全免费】
评论区
原来可以这样? 通过ARIMA模型分析,我们可能预测未来一周的日均订单量分别为:7月31日:2550单,8月1日:2600单,8月2日:2650单,8月3日:2700单,8月4日:2750单,8月5日:2800单,8月6日:2850单。
按照你说的, 这意味着每增加1000元广告投放,销售额预计增加4500元。
确定是这样吗? 选择不同的模型:不同的模型适用于不同的数据和预测目标。